
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 코로나백신피해야할대상
- CES2021LG
- 자율주행오로라
- 코로나백신대상
- CES2021
- 김래아
- 드론배송시작
- 우버자율주행
- 코로나백신
- UAMT
- 오로라자율주행
- 기술경영
- 해외UAM
- 아마존자율주행
- 우버 매각
- 월마트드론
- 자율주행
- 6G
- 오로라이노베이션
- 스마트시티
- 자율주행차량
- 로보택시
- Starlink
- 자율주행택시
- UAM
- 에어택시
- 완전자율주행
- smart_city
- UAM사례
- 로봇택시
- Today
- Total
RDX 공식블로그
인간의 바디랭귀지를 학습하는 자율주행차 본문
게임 개발자가 모션 캡쳐 기술을 사용해 크루즈의 자율차량을 교육하여 제스처를 이해
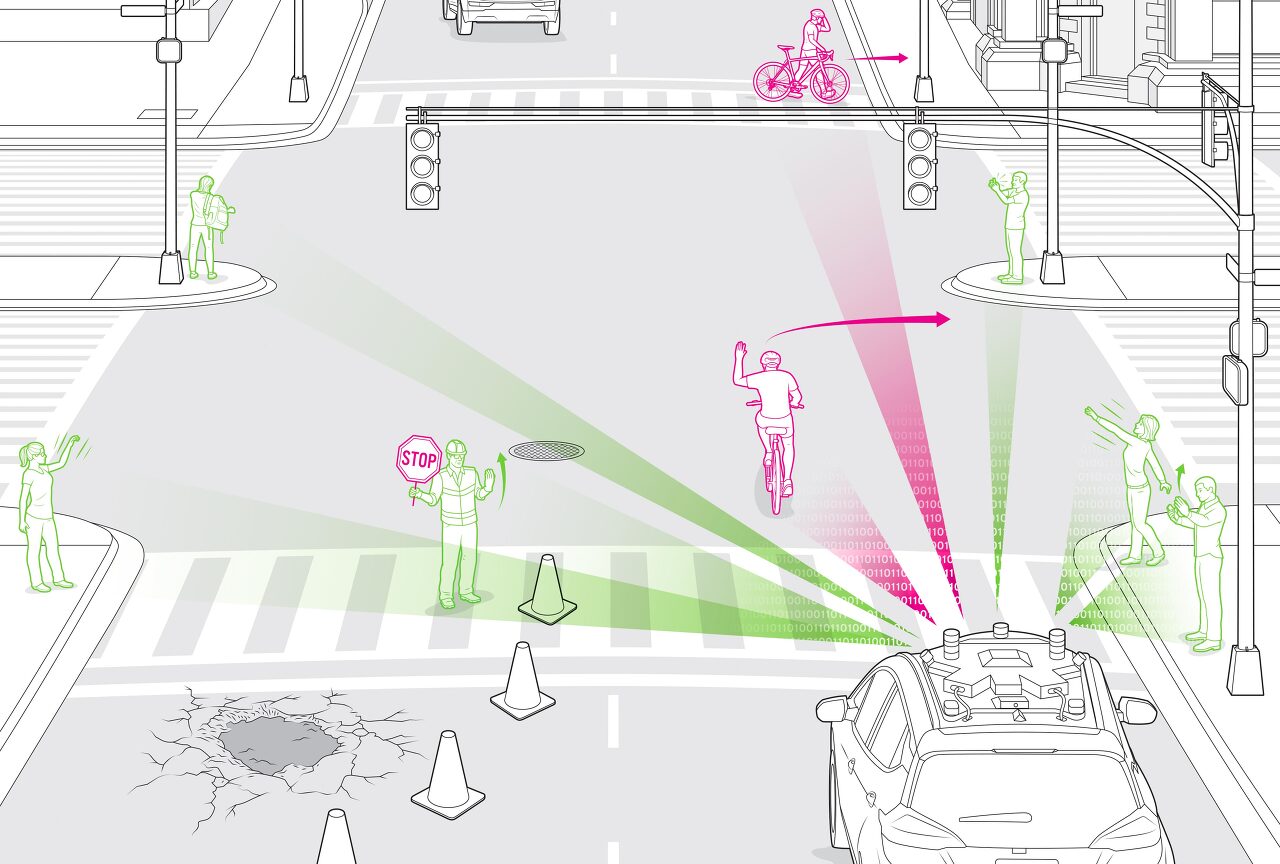
(2020.08.26.) 4차선 도로가 두 개로 좁아져 큰 포트홀을 수리하는 노동자들을 수용할 수 있다. 한 노동자는 오른손으로 차를 흔들면서 왼손에 느슨하게 정지 신호를 잡고 있다. 인간 운전자들은 그 몸짓이나 표지를 보더라도 멈추지 않고 부드럽게 앞으로 나아간다. 그러나 이런 상황에서 자율주행차가 궤도에 진입하면 멈추어 설 것이다. 정지 표지판과 어떻게 반응해야하는지는 이해하지만 인간의 손동작은 훨씬 복잡하다. 운전자들은 매일 신체 언어를 사용하는 이런 복잡한 상황에 직면한다. 신호등을 기다리며 건널 준비를 하고 있는 보행자가 핸드폰을 확인하려고 멈춰 서서 우회전하는 차 앞으로 손을 흔든다. 또 다른 보행자가 손을 들어 건너편 친구에게 손을 흔들어 보지만 계속 움직인다. 인간 운전자는 이러한 제스처를 한눈에 해독할 수 있다. 교통 흐름을 방해하지 않고 운전을 안전하고 원활하게 진행하려면 자율주행 자동차가 행인의 제스처와 바디랭귀지 같은 예상치 못한 상황에서 운전자에게 안내하는 데 사용되는 일반적인 손동작을 이해해야 한다. 이것들은 인간이 별 생각 없이 반응하는 신호들이지만, 주변 세상에 대해 배우고 있는 컴퓨터 시스템에게는 새로운 도전이다.
전 세계의 자율주행차 개발자들은 몇 년 동안 자율주행차들을 자전거 이용자들의 신호에 초점을 맞추어 최소한 기본적인 손동작들을 이해하도록 가르쳐 왔다. 일반적으로 개발자들은 실제 상황을 파악하고 어떻게 대처해야 하는지를 이해하여 차량의 능력을 향상시키기 위해 머신러닝에 의존한다. 크루즈는 200대 이상의 자율주행차단에서 그 데이터를 수집하는데 이 차량들은 지난 7년 동안 매년 수십만 마일을 운행해 왔다. COVID-19 이전, 차량단은 단지 차량 충전(모든 차량이 전기차량임)과 정기적인 유지보수를 제외하고 24시간 내내 도로를 달렸다. 크루즈의 자율차들은 미국에서 가장 복잡한 운전 환경 중 하나인 샌프란시스코에서 테스트하며 빠르게 배우고 있다.
하지만 자율차는 현실세계에서 중요한 제스처를 충분히 자주 경험하지 않았기 때문에 기계 학습 모델들이 항상 충분한 데이터를 가지고 있지 않다는 것을 인식하게 되었다. 자율차량은 이런한 각각의 상황에 다른 각도와 거리 그리고 다른 조명 조건 즉, 엄청난 수의 가능성을 생성하는 제약 조건들의 조합에서 인식할 필요가 있다. 만약 차량의 실제 경험만 의존한다면 이런 경우에 대한 충분한 정보를 얻으려면 몇 년이 걸릴 것이다.
크루즈는 데이터 갭에서 아이디어를 얻었다. 바로 게임 개발자들이 캐릭터를 만들기 위해 사용하는 인간 제스처의 모션 캡쳐(또는 mo-cap) 기술이다. 크루즈는 게임개발자들을 고용해 세부 세계를 시뮬레이션하는 데 필요한 전문 지식을 제공해 왔으며, 차량들이 제스처를 이해하는 데 사용할 데이터를 포착하고 있다.
먼저, 데이터 수집팀은 사람들이 자신의 몸을 사용하여 다른 사람들과 교류하는 방법, 예를 들어 택시를 부를 때, 걷다가 전화를 할 때, 또는 보도 공사를 피하기 위해 거리로 나설 때 등 포괄적인 목록을 작성하기 시작했다. 또한 친구에게 손을 흔드는 보행자처럼 자율 차량이 명령으로 오해할 수도 있는 내용도 넣었다. 차량 옆 차선에서 차고를 향해 차에게 손을 흔드는 주차요원과 차를 임시로 멈추라는 팻말을 들고 있는 건설노동자 등 다른 복잡한 제스처들도 포함했다.

결국 제스처를 통해 전달되는 정지, 이동, 좌회전, 우회전, 그리고 셀카를 찍거나 배낭을 내려놓는 것과 같은 차량과 관련 없는 일반적인 동작까지 총 5가지 주요 메시지 리스트를 생각해냈다. 일반적으로 받아들여지는 미국식 제스처를 사용하였으며 샌프란시스코에서 테스트하고 있기 때문에 자동차가 오른쪽에서 주행한다고 가정했다. 물론, 사람들이 이러한 메시지를 보내기 위해 사용하는 제스처는 균일하지 않기 때문에, 처음부터 우리의 데이터셋에 5가지 예시 이상의 것이 포함되어야 한다는 것을 알고 있었지만 얼마나 되는지 확신할 수 없었다.
이 데이터셋을 만들려면 모션 캡쳐 기술을 사용해야 한다. 모캡 시스템에는 광학 시스템과 비광학 두 종류가 있다. 광학 버전의 모캡은 무대를 둘러싸고 있는 큰 격자 모양의 구조 위에 분산된 카메라를 사용한다. 이들 카메라에서 나오는 비디오 스트림은 실험참가자가 착용한 전신 수영복에 비주얼 마커의 3D 위치를 삼각측량하는 데 사용될 수 있다. 이 시스템에는 얼굴 표정을 포함한 매우 상세한 캡처를 만들어낼 수 있다. 2009년 영화 아바타에서처럼 영화배우들이 비인간적인 캐릭터를 연기할 수 있게 하고, 스포츠를 주제로 한 비디오게임의 발전을 위해 게임업계가 선수들의 움직임을 기록하도록 하는 것처럼 말이다.
광학 모션 캡처는 복잡한 멀티카메라 설정이 있는 스튜디오 설정에서 수행되어야 한다. 하지만 크루즈는 비광학적, 센서 기반의 모션 캡쳐 버전을 선택했다. 미세전자기계시스템(MEMS)에 의존하는 이 기술은 휴대용 무선으로 전용 스튜디오 공간이 필요 없다. 그것은 우리에게 많은 유연성을 주고 스튜디오에서 실제 위치로 그것을 가져갈 수 있게 해준다.
모캡 슈트는 각각 머리와 가슴, 그리고 각 엉덩이, 어깨, 상팔, 팔뚝, 다리를 포함한 몸의 주요 지점에 부착된 19개의 센서 패키지가 장착되어 있다. 각각의 패키지는 동전 정도의 크기로, 가속도계, 자이로스코프, 자력계를 포함하고 있다. 이것들은 모두 배터리 팩, 제어 버스, 와이파이 라디오가 들어 있는 벨트에 연결되어 있다. 센서 데이터는 전용 소프트웨어를 실행하는 노트북으로 무선으로 흘러들어와 엔지니어가 실시간으로 데이터를 보고 평가할 수 있게 해준다.
크루즈 엔지니어링팀에서 키, 몸무게, 성별 등 신체 특성이 다른 5명의 자원봉사자를 모집해 양복을 입게 한 뒤 전자 간섭이 비교적 자유로운 곳에서 검증하였으며 239개의 30초짜리 클립을 만들었다. 각 참가자들은 모캡 시스템을 보정하기 위해 T-pose(직립, 다리를 모으고 팔을 옆으로 내밀고 서 있음)으로 시작하여 실제 데이터에서 만들어 낸 제스처 리스트를 이리저리 옮겨가며 한 동작씩을 했다. 7일 동안, 다섯 명의 참가자들은 각각의 손을 따로 그리고 어떤 경우에는 함께 사용하면서 제스쳐 세트를 반복해서 실행 했다. 참가자들에게도 각기 다른 강도로 표현해 달라고 당부했다. 예를 들어, 건설 지역에서 너무 빨리 달리는 차에 급정거를 알리는 제스처에는 강도가 높을 것이다. 그 강도는 차가 속도를 늦추고 서서히 멈춰야 한다는 것을 나타내는 움직임의 경우 더 낮을 것이다.
테스트 후 엔지니어들은 기계 학습 모델에 공급될 데이터를 준비했다. 첫째, 추가 노이즈 없이 모든 제스처가 올바르게 기록되었는지, 잘못 회전한 센서가 불량 데이터를 제공하지 않았는지 검증했다. 그런 다음 엔지니어들은 각 동작 순서를 순서대로 각 프레임의 공동 위치와 방향을 식별하는 소프트웨어를 통해 실행했다. 이러한 위치는 원래 3차원으로 캡처되었기 때문에 소프트웨어는 각 시퀀스의 여러 2D 관점으로 계산할 수 있다. 그 기능을 통해 10개의 다른 방향을 시뮬레이션하기 위해 점들을 점진적으로 회전시킴으로써 제스처를 확장할 수 있다. 엔지니어들은 실제상황을 시뮬레이션 하기 위해 신체의 다양한 포인트들을 무작위로 떨어뜨려 훨씬 더 많은 변화를 만들어냈다. 그리고 다른 시야각들을 만들기 위해 나머지 포인트들을 다시 점진적으로 회전시켰다.
다양한 사람들이 다른 관점으로 보는 광범위한 제스처를 제공하는 것 외에도, 모션 캡쳐는 깨끗하게 데이터를 제공했다. 인간의 자세의 골격 구조는 옷의 스타일이나 색깔, 조명 조건과 상관없이 일관된다. 이 깨끗한 데이터를 통해 우리는 기계 학습 시스템을 보다 효율적으로 교육할 수 있다.
일단 차량이 모션 캡쳐된 데이터에 대해 훈련을 받으면 도시운전이 제공하는 다양한 시나리오를 탐색할 수 있는 더 나은 준비를 갖추게 될 것이다. 이런 사례 중 하나가 도로 공사이다. 샌프란시스코는 항상 수많은 건설 프로젝트가 진행 중인데, 이는 차량이 교통을 통제하는 공사 근로자들과 자주 마주한다는 것을 의마한다. 크루즈의 제스처 인식 시스템을 이용하여 자동차는 각각의 손동작을 이해하면서 작업자를 안전하게 지나갈 수 있을 것이다.
예를 들어 도로 근로자 3명이 자율주행차가 타려던 차선을 막고 있는 상황이다. 작업자 중 한명은 교통상황을 지시하고 나머지 두 명은 도로 피해 상황을 평가하고 있다. 교통을 통제하는 노동자는 한 손에 표지판을 들고 있는데 ‘정지’표시판처럼 생긴 표지판에 ‘느리게’라고 쓰여있다. 다른 손에는 앞으로 나아가라고 손짓한다. 교차로를 안전하게 건너기위해 자율차는 교통 통제하는 사람으로 인식할 것이다. 차량은 다른 차선으로 방향을 바꿔 앞으로 나아가고, 교차로 반대편에서 정차하지만 우회전하는 것처럼 보이는 차는 무시하라는 뜻으로 그의 제스처를 올바르게 해석할 것이다. 이런 것들이 우리 차가 교차로에서 누군가를 보더라도 계속 전진할 수 있다는 것을 이해할 수 있게 해 준다.
자율주행차들이 인간의 제스처를 이해하도록 훈련하는 것은 시작에 불과하다. 이러한 시스템은 사람의 기본적인 움직임 이상의 것을 감지할 수 있어야 한다. 크루즈는 테스트 차량은 현실에서 운행할 때 수집한 비디오를 사용하여 꾸준히 제스처 인식 시스템을 테스트하고 있다. 한편, 우리는 인간이 자전거와 같은 다른 물체를 운반하거나 밀어내는 개념을 이해하도록 우리의 시스템을 훈련하기 시작했다. 사람이 자전거를 밀면 보통 사람이 자전거를 타는 것과 다르게 행동하기 때문에 이것은 중요하다.
또한 크루즈는 자동차들이 자전거 타는 사람들의 동작을 더 잘 이해할 수 있도록 데이터 세트를 확대할 계획이다. 예를 들어, 팔꿈치를 90도 각도로 한 왼손은 자전거 타는 사람이 오른쪽으로 돌 것이라는 것을 의미하다. 이미 차량들은 자전거 타는 사람들을 인식하고 있고 그들을 위한 공간을 만들기 위해 자동으로 속도를 줄인다. 인간의 몸짓이 무엇을 의미하는지 안다면 자율차들은 완전히 멈추지 않으며 불필요한 교통 체증을 일으키지 않고 자전거 타는 사람들에게 신호를 보내는 동작 등을 할 수 있는 충분한 공간을 줄 수 있도록 할 것이다.(물론 차량은 인간이 의도를 알리지 않고 자전거 타는 사람들이 여전히 예상치 못한 회전을 하는 경우를 조심하고 있다.)
자율주행차는 앞으로 몇 년 동안 우리가 살아가는 방식을 바꿀 것이다. 그리고 머신러닝은 이 발전에서 우리를 아주 먼 길로 인도해 주었다. 그러나 모션 캡쳐와 같은 기술의 창의적인 사용은 자율주행이 도시에 더 잘 공존하도록 더 빨리 가르칠 수 있게 해줄 것이며, 우리의 도로를 모두를 위해 더 안전하게 만들 것이다.
[출처]
Self-Driving Cars Learn to Read the Body Language of People on the Street
Game developers use motion-capture tech to teach Cruise’s autonomous vehicles to understand gestures
spectrum.ieee.org
Edited by Lucy
'Tech.News' 카테고리의 다른 글
| 성공적인 로보택시 제공을 위한 6가지 고려사항 (0) | 2020.09.14 |
|---|---|
| FEV, CAV 개발을 위한 Co-simulation의 선두주자 (0) | 2020.09.10 |
| 일본 자율주행 버스 테스트 얼굴 인식으로 결제 가능 (0) | 2020.09.07 |
| NHTSA, 미국 자율차 테스트 정보 한눈에 볼 수 있는 웹사이트 개설 (0) | 2020.09.07 |
| Apple, 제어 받는 도어와 VR 시스템 갖춘 자율주행차 개발 중 (0) | 2020.09.04 |



